With SQL Server 2025, Microsoft introduces vector support as a native engine feature: a built-in VECTOR(dim) data type, dedicated vector functions, and an approximate vector index tightly integrated into the optimizer. From a SQL Server point of view, this feels natural—vectors become another first-class datatype, queried via explicit functions such as VECTOR_DISTANCE or VECTOR_SEARCH, and backed by a specialized index structure.
In PostgreSQL, the same capability is delivered through pgvector, an extension rather than a core feature. However, pgvector is not a thin add-on. It integrates deeply into PostgreSQL’s planner and executor. Instead of introducing new query syntax, it extends existing SQL concepts: expressions, operators, ordering, and indexes.
👉 If you want to learn more about SQL Server 2025 and PostgreSQL, I highly recommend to have a look on my upcoming online trainings about it.
pgvector vs. SQL Server 2025
In SQL Server 2025, vector operations are explicit and function-driven. Distance is computed through scalar functions, and approximate nearest-neighbor search is initiated through a dedicated construct. The query text clearly communicates intent: this is a vector operation, and the engine handles it specially.
pgvector takes a different approach. It introduces a new data type, vector(n), and a set of operators that compute distance between vectors. The most important of these operators is <->.
The <-> operator represents the distance between two vectors. Conceptually, it fills the same role as VECTOR_DISTANCE in SQL Server 2025, but it is expressed as an operator, not a function. That distinction is crucial:
- <-> returns a numeric value
- PostgreSQL can sort by it
- PostgreSQL can use an index to satisfy that sort
A typical pgvector query therefore looks like this:
SELECT DocumentID, Title FROM Documents
ORDER BY Embedding <-> '[0.2,0.4,0.6]'::VECTOR
LIMIT 10;From a SQL Server perspective, this is equivalent to ordering by a computed scalar expression and applying TOP (10). The difference is that PostgreSQL’s planner understands that certain indexes (HNSW or IVFFlat) can satisfy this ordering efficiently. There is no direct analogue to <-> in SQL Server 2025, because SQL Server expresses distance through functions rather than operators. Functionally, however, both systems are solving the same problem: rank rows by similarity and return the top K.
HNSW in pgvector
The most commonly used index type in pgvector is HNSW, short for Hierarchical Navigable Small World graph. Understanding HNSW is essential to understanding pgvector’s performance characteristics.
Exact nearest-neighbor search in high-dimensional space does not scale. Computing the distance from a query vector to every row is equivalent to a full table scan with an expensive computation. HNSW exists to make this problem tractable at hundreds of thousands or millions of vectors.
HNSW is an approximate nearest-neighbor (ANN) algorithm. It trades perfect accuracy for dramatically lower latency and predictable performance, which is exactly what workloads such as semantic search, recommendation systems, and RAG pipelines require. HNSW organizes vectors into a layered graph:
- Upper layers are sparse and allow long “jumps” across the vector space
- Lower layers are denser and allow fine-grained local navigation
- A query starts at the top layer, greedily walks the graph, and descends layer by layer until it reaches a small candidate set near the query vector
n pgvector, HNSW is exposed as an index access method. When you create an HNSW index, you are telling PostgreSQL: this ordering by <-> can be approximated efficiently using a graph-based structure:
CREATE INDEX documents_embedding_hnsw
ON Documents
USING hnsw (embedding vector_l2_ops);The operator class (vector_l2_ops) defines what <-> means for this index – in this case, Euclidean (L2) distance.
A pgvector example
This walkthrough mirrors how a SQL Server professional would evaluate any new indexing feature: establish a baseline, add an index, and compare execution plans. Let’s enable the extension in the first step:
CREATE EXTENSION IF NOT EXISTS vector;This registers the vector(n) type and the distance operators, including <->.
In the next step we use a simple multi-tenant table, because filtered nearest-neighbor queries are where ANN behavior really matters. We also insert some test data.
-- Create a simple Documents table
CREATE TABLE documents
(
DocumentID BIGSERIAL PRIMARY KEY,
TenantID INT NOT NULL,
Title TEXT NOT NULL,
Embedding VECTOR(3) NOT NULL
);
-- Insert some data
INSERT INTO Documents (TenantID, Title, Embedding)
SELECT
(gs % 100) + 1,
format('doc-%s', gs),
ARRAY[
random()::real,
random()::real,
random()::real
]::vector(3)
FROM generate_series(1, 200000) AS gs;
-- Update the statistics
ANALYZE Documents;Without a vector index, PostgreSQL must scan the entire table and compute distances for every row.
-- A simple query
EXPLAIN (ANALYZE)
SELECT DocumentID, Title FROM Documents
ORDER BY Embedding <-> '[0.2,0.4,0.6]'::VECTOR
LIMIT 10;For a SQL Server DBA, this should look like a classic “compute and sort” plan – exactly what you would expect without a supporting index.
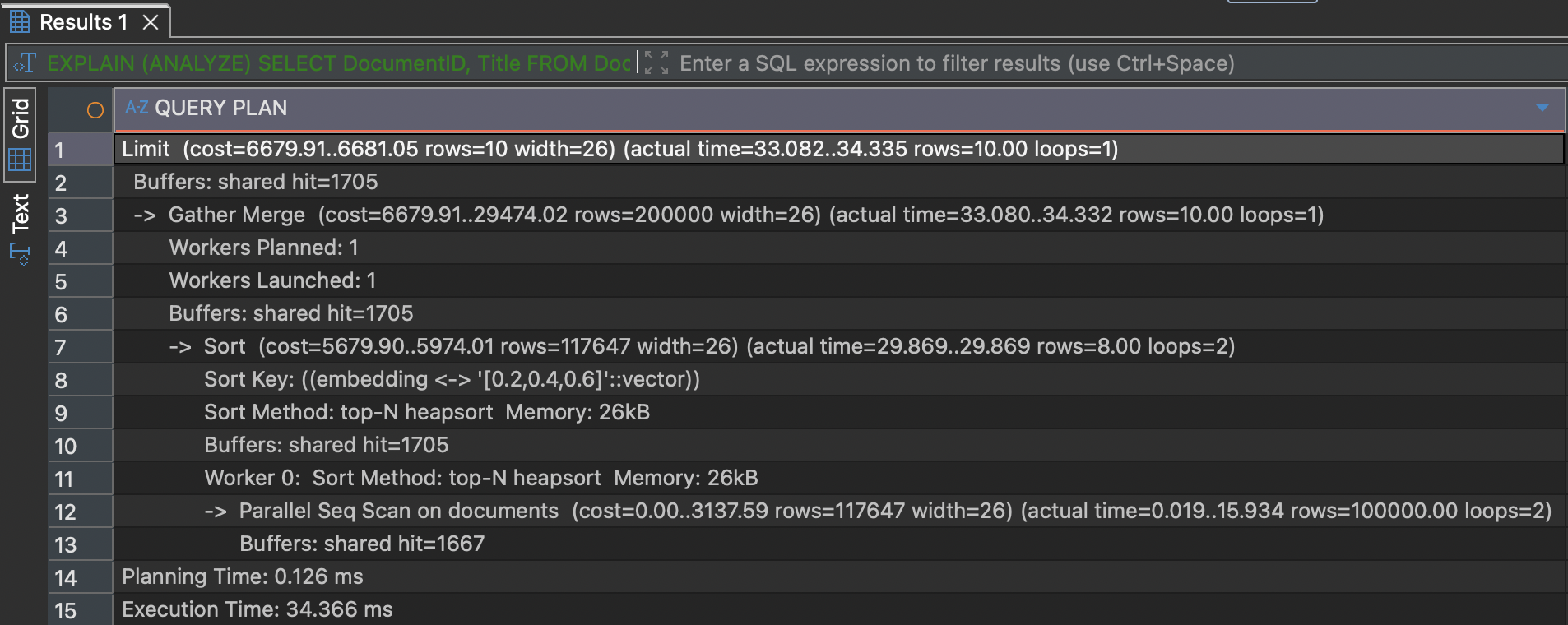
On my system, this query runs for about 30 ms. Let’s create now a supporting HNSW index for this query:
-- Create a supporting index
CREATE INDEX documents_embedding_hnsw
ON Documents
USING hnsw (embedding vector_l2_ops);Re-running the same query now typically shows an index-driven plan with dramatically lower execution time and I/O.
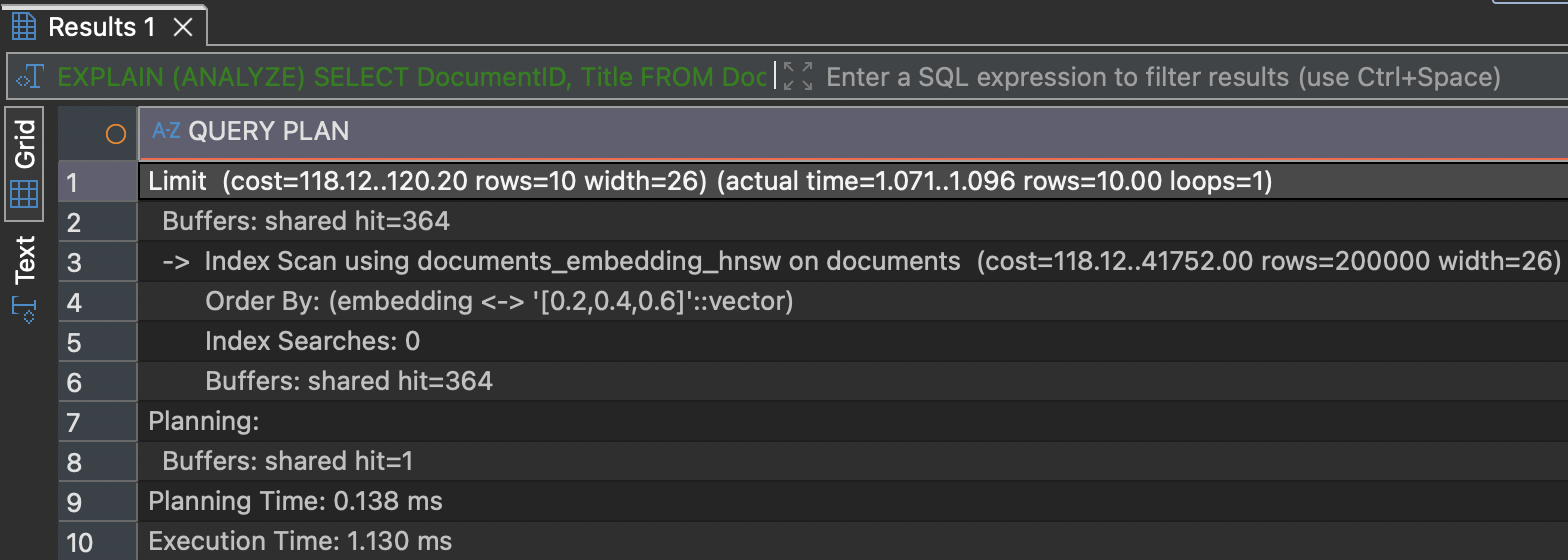
As you can see, the query runs now for only about 1ms, which is a quite impressive improvement.
👉 If you want to learn more about SQL Server 2025 and PostgreSQL, I highly recommend to have a look on my upcoming online trainings about it.
Summary
SQL Server 2025 and PostgreSQL with pgvector approach vector search from different angles. SQL Server emphasizes native types and explicit vector functions. PostgreSQL emphasizes composability: vectors become sortable values, <-> becomes a first-class ordering operator, and HNSW becomes another index access method the planner can reason about.
For a SQL Server DBA or developer, pgvector is best understood not as a foreign concept, but as PostgreSQL extending its relational model into high-dimensional space. Execution plans still matter. Statistics still matter. Filters still matter. The tools are different, but the discipline is the same.
Thanks for reading,
-Klaus