PostgreSQL is a powerful, feature-rich database system, but its architecture differs in significant ways from Microsoft SQL Server. One of the most important differences lies in how connections are handled. While SQL Server multiplexes many client requests across worker threads inside a single process, PostgreSQL spawns a dedicated backend process for every client connection. This design simplifies isolation and debugging but also means that a large number of client connections can overwhelm the database server quickly.
If you are interested in learning how to transition your SQL Server knowledge to PostgreSQL, I highly recommend to check-out my Live Training PostgreSQL for the SQL Server Professional that I run on November 26 – 27, 2025.
For web applications and microservices, where connections are often short-lived and numerous, PostgreSQL alone can struggle to scale. This is where PgBouncer, a lightweight connection pooler, becomes an essential component. In this post, we will set up PostgreSQL together with PgBouncer using Docker Compose on macOS, explore the configuration files, and demonstrate why PgBouncer is so critical in a PostgreSQL environment.
Why PostgreSQL Needs PgBouncer (and SQL Server Does Not)
In SQL Server, connection management is largely invisible to the developer. Thousands of concurrent connections can be sustained because the server internally manages them through a pool of worker threads. The overhead per connection is relatively small.
In PostgreSQL, every client connection results in a new operating system process. Each process consumes memory, incurs context switching overhead, and makes rapid connect/disconnect patterns very expensive. Applications that open hundreds or thousands of concurrent connections can easily overwhelm PostgreSQL, even on powerful hardware.
PgBouncer solves this by multiplexing many client connections onto a much smaller number of actual PostgreSQL connections. To the application, PgBouncer looks just like a PostgreSQL server. To PostgreSQL, PgBouncer appears as a handful of persistent clients. The result is reduced memory usage, faster connection establishment, and better throughput under high concurrency.
The Docker Compose Setup
We will create a small environment with two services: PostgreSQL and PgBouncer. PostgreSQL will run with a deliberately low maximum number of connections so that the benefit of pooling becomes obvious. PgBouncer will sit in front of it, configured in transaction pooling mode.
services:
db:
image: postgres
container_name: pgdemo-db
environment:
POSTGRES_USER: app
POSTGRES_PASSWORD: passw0rd1!
POSTGRES_DB: appdb
command:
- "postgres"
- "-c"
- "max_connections=100"
- "-c"
- "shared_buffers=512MB"
ports:
- "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U app -d appdb"]
interval: 5s
timeout: 3s
retries: 20
pgbouncer:
image: edoburu/pgbouncer
container_name: pgdemo-pgbouncer
depends_on:
db:
condition: service_healthy
environment:
DB_USER: app
DB_PASSWORD: secret
DB_HOST: db
DB_NAME: appdb
volumes:
- ./pgbouncer.ini:/etc/pgbouncer/pgbouncer.ini:ro
- ./userlist.txt:/etc/pgbouncer/userlist.txt:ro
ports:
- "6432:6432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U admin -h 127.0.0.1 -p 6432 -d pgbouncer || exit 1"]
interval: 5s
timeout: 3s
retries: 20The db service runs PostgreSQL 16. We use environment variables to create a default user (app) with password secret and a database (appdb). The command section overrides the default settings so that PostgreSQL starts with only 100 maximum connections. This limit makes it easier to observe the scaling problem. Port 5432 is exposed so that we can connect directly from the host.
The healthcheck ensures that the service is marked healthy only after pg_isready confirms that PostgreSQL is accepting connections.
The pgbouncer service uses the popular edoburu/pgbouncer image. It depends on the db service being healthy. We mount our own configuration files from the host into the container. PgBouncer listens on port 6432, which is mapped to the host so that applications can connect through it. Its healthcheck also uses pg_isready to confirm that PgBouncer itself is responsive.
The PgBouncer Configuration Files
PgBouncer requires two files: the main configuration (pgbouncer.ini) and a list of users and passwords (userlist.txt). Let’s start with the pgbouncer.ini file:
[databases]
appdb = host=db port=5432 dbname=appdb
[pgbouncer]
listen_addr = 0.0.0.0
listen_port = 6432
auth_type = plain
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admin
stats_users = admin
pool_mode = transaction
default_pool_size = 50
min_pool_size = 10
reserve_pool_size = 5
max_client_conn = 10000
server_reset_query = DISCARD ALL
ignore_startup_parameters = extra_float_digits
log_connections = 1
log_disconnections = 1
log_pooler_errors = 1The [databases] section maps a logical database name to the actual PostgreSQL service. Here, any client that connects to appdb will be forwarded to the container db on port 5432, targeting the database also called appdb.
The [pgbouncer] section defines how PgBouncer itself operates. It listens on all interfaces (0.0.0.0) at port 6432. Authentication is configured with auth_type = plain, which is suitable for a demo but not for production. The auth_filepoints to the userlist.txt. We declare admin as an admin and stats user so that we can run management commands like SHOW POOLS.
The most important option is pool_mode. Setting this to transaction means that a real PostgreSQL connection is assigned for the duration of a transaction and then returned to the pool immediately after a commit or rollback. This is very efficient for workloads with short transactions. The default_pool_size is set to 50, meaning PgBouncer will open up to 50 real connections to PostgreSQL. No matter how many client connections arrive, only 50 backends will exist on PostgreSQL. Other options control minimum pools, reserve pools, and maximum client connections (here, 10000). The server_reset_query cleans up the session before it is reused. The following listing shows you the userlist.txt file.
"admin" "adminpass"
"app" "passw0rd1!"This file lists usernames and passwords that PgBouncer accepts. The client authenticates against PgBouncer, and PgBouncer uses the same credentials to connect to PostgreSQL. For a demo, plaintext is fine.
Demonstrating the Effect of PgBouncer
We can start now the Docker Compose environment with the simple command: docker compose up -d

With the environment up and running, we can initialize the our test database with pgbench: pgbench -h localhost -p 5432 -U app -i -s 5 appdb
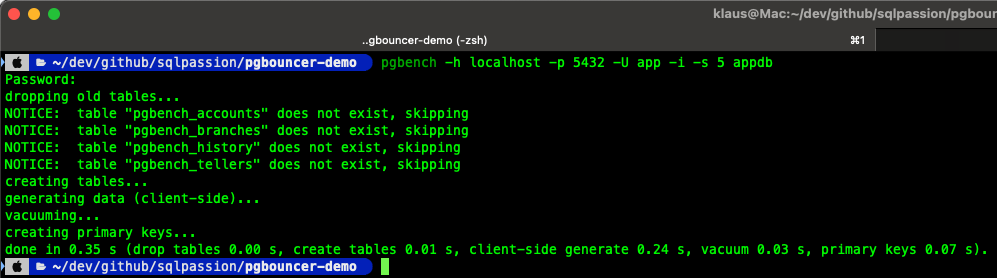
When we run a benchmark directly against PostgreSQL with the -C option, which forces every transaction to create a new connection, PostgreSQL quickly hits its max_connections limit and throughput collapses. The operating system spawns many backend processes, memory usage rises, and latency increases.
pgbench -h localhost -p 5432 -U app -M simple -C -c 200 -j 8 -T 30 appdb
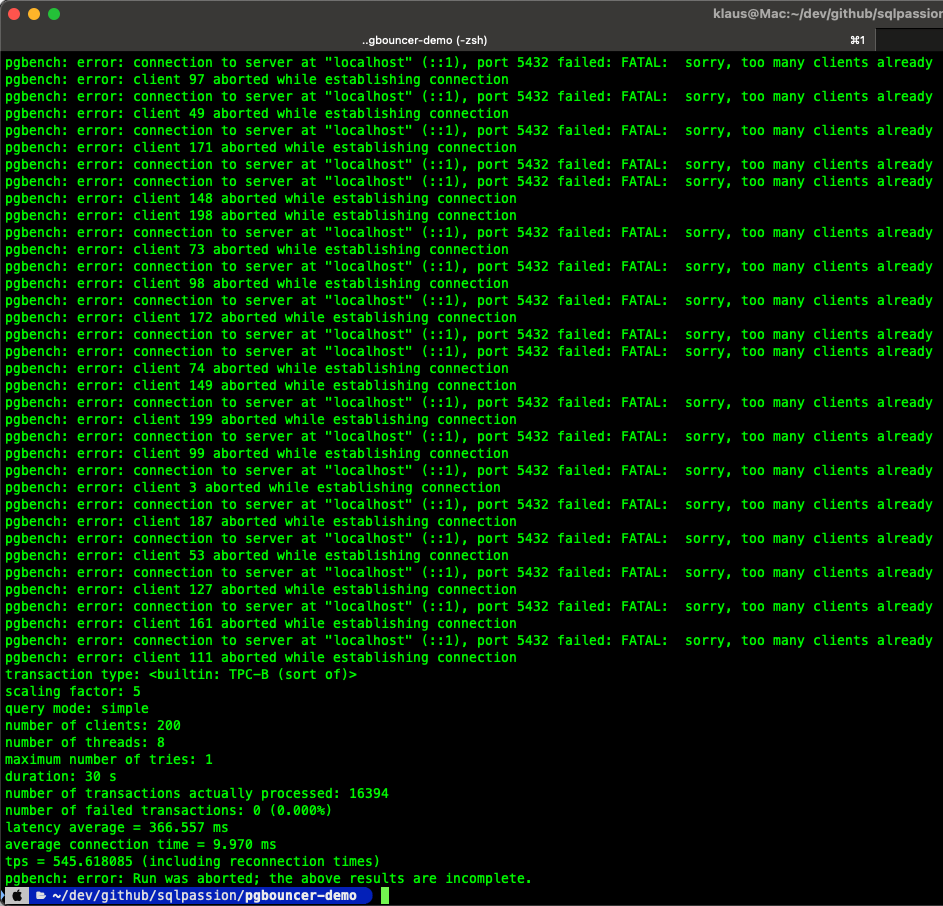
As you can see from the output, we get a lot of errors, because too many clients have already connected to PostgreSQL, which is limited by its max_connection limit setting. In sum I got here with this test run around 545 transactions per second (TPS).
When we repeat the same benchmark through PgBouncer on port 6432, the experience is entirely different. The client still opens and closes connections rapidly, but PgBouncer simply multiplexes these virtual connections onto 50 persistent PostgreSQL backends. From PostgreSQL’s perspective, the workload is stable and limited. Transactions per second increase, and the server is no longer overwhelmed by connection storms.
pgbench -h localhost -p 6432 -U app -M simple -C -c 200 -j 8 -T 30 appdb
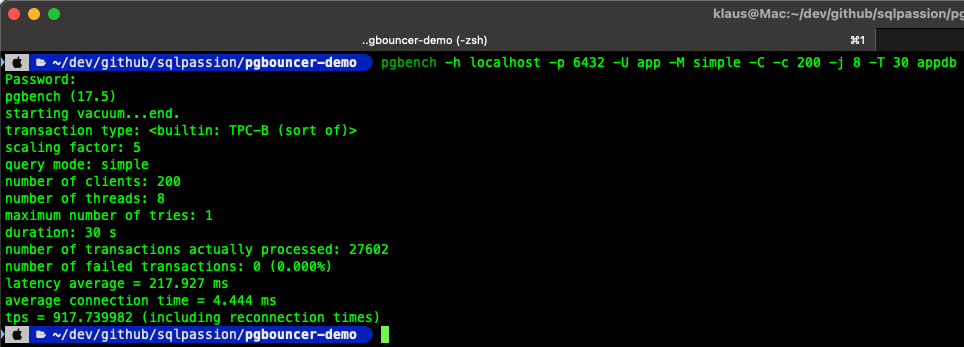
As you can see from the above picture, the error messages are gone, and the transactions per second increased to 917 – almost the double amount of throughput! You can also check the number of backend connections during a test run through pg_stat_activity – as shown in the following picture:
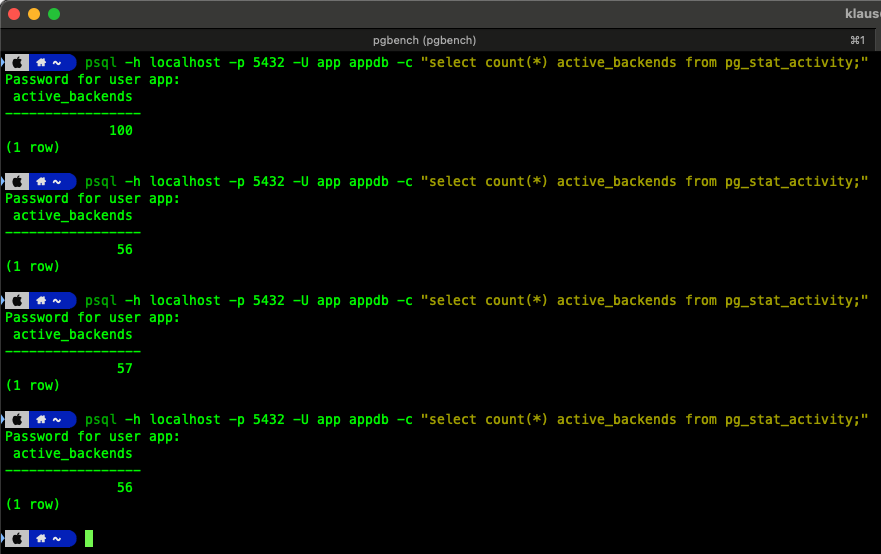
The result of the first execution was shown during the test run without connection pooling – we have 100 active backend connections. The maximum that is possible through the current configuration. On the next 3 executions we have only around 56 – 57 backend connections, because I queried pg_stat_activity during the use of PgBouncer and its connection pooling mechanism.
Summary
PostgreSQL’s process-per-connection model makes it vulnerable to workloads with high numbers of concurrent or short-lived connections. Microsoft SQL Server’s thread-based architecture does not suffer in the same way, which is why SQL Server users rarely think about external connection pooling. In PostgreSQL, however, connection poolers like PgBouncer are not optional extras but essential components in any serious deployment.
If you are interested in learning how to transition your SQL Server knowledge to PostgreSQL, I highly recommend to check-out my Live Training PostgreSQL for the SQL Server Professional that I run on November 26 – 27, 2025.
By setting up PostgreSQL and PgBouncer with Docker Compose on macOS, you can observe this difference directly. A small configuration file and a few containers are enough to show why PgBouncer is critical, how it is configured, and how dramatically it improves scalability under load.
Thanks for your time,
-Klaus