A few weeks ago I had a customer engagement, where the customer wanted to implement Nested Partitioned Views. Before we go into the details of this approach and if it could work, I want to give you an overview about the requirements, and why the customer wanted to have Nested Partitioned Views.
The main idea was that the customer had to implement their SQL Server database for both Standard and Enterprise Edition. With the Enterprise Edition the customer used a combination of Partitioned Views and Partitioned Tables, as you can see it from the following picture.
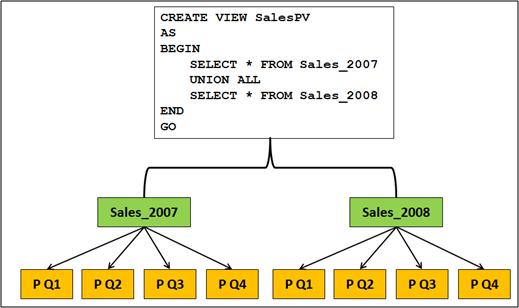
Some of you might ask, why the heck you want to implement such a scenario. The answer is easy: Partitioned Views itself have some disadvantages, and on the other hand Partitioned Tables also have some disadvantages. But when you combine then you will get the benefits from BOTH worlds. The following list describes the pros and cons of Partitioned Views in SQL Server.
-
Pros
- Available on any Edition of SQL Server
- Each table has its own better Statistics
- Index Rebuilds of any table is an ONLINE operation (when done on Enterprise Edition)
-
Each table can be indexed independently
- Operational Data
- Historical Data
-
Cons
- Lots of tables to administer
- Indexes must be created on individual tables
- Check Constraints are needed for Table Elimination
- Gaps and overlapping values are possible
The following list describes the pros and cons of Partitioned Tables in SQL Server.
-
Pros
- Only one table to administer
- Gaps and overlapping values are NOT possible
- Completely transparent
-
Cons
- Available only on the Enterprise Edition of SQL Server
-
Table-Level Statistics
- Less accurate on larger Partitioned Tables
- Filtered Statistics can help here…
-
Partition Level Index Rebuilds are OFFLINE operations
- Only the whole Partitioned Table can be rebuild ONLINE
-
Supports Partitioning only over a single column
- Persisted Computed Columns are needed
As you can see from this list, there are a lot of disadvantages of Partitioned Tables, especially in the area of maintenance (less accurate Statistics, Partition Level Index Rebuilds). As you have seen in the previous figure, you can achieve a very powerful solution, when you combine Partitioned Views with Partitioned Tables.
Because the customer also had to support the database on the Standard Edition of SQL Server (where Partitioned Tables are not available), they just wanted to substitute the Partitioned Tables with Partitioned Views – so in the final solution you just have Partitioned Views inside Partitioned Views – just Nested Partitioned Views. The following picture illustrates this concept.
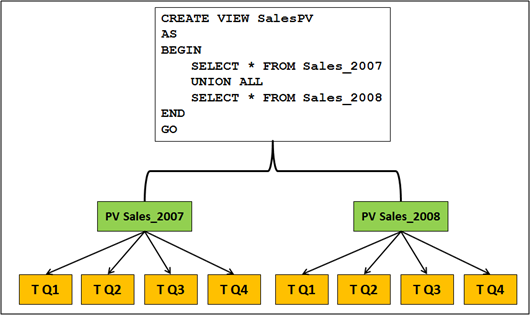
So the question was now, if this could be done with SQL Server? Of course, you can make it this way, but what’s about performance? SQL Server can use with a single Partitioned View Table Elimination when each participating table has a corresponding CHECK constraint defined. Therefore SQL Server only has to query the necessary tables – it’s almost the same concept as Partition Elimination with Partitioned Tables. But would Table Elimination work with Nested Partitioned Views? Because there is no chance to define a CHECK constraint on the inner Partitioned Views…
Before I give you the ultimate answer on that question, I want to walk through a complete scenario, how you can setup and implement Nested Partitioned Views as illustrated in the last picture. In the first step we are creating a new database, and adding 2 new file groups to it, where the data of 2007 and 2008 is stored.
USE master GO -- Create a new database CREATE DATABASE VLDB ON PRIMARY ( NAME = N'VLDB', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\VLDB.mdf', SIZE = 5072KB, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'VLDB_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\VLDB_log.ldf', SIZE = 2048000KB, -- Initialize the log with 2GB, this gives us 16 VLFs FILEGROWTH = 10% ) GO -- Create a new file group for the 2007 sales data ALTER DATABASE VLDB ADD FILEGROUP Sales2007FG GO -- Add a new file to the previous created file group ALTER DATABASE VLDB ADD FILE ( NAME = 'Sales2007_Data', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\Sales2007_Data.ndf', SIZE = 300, FILEGROWTH = 10% ) TO FILEGROUP Sales2007FG GO -- Create a new file group for the 2008 sales data ALTER DATABASE VLDB ADD FILEGROUP Sales2008FG GO -- Add a new file to the previous created file group ALTER DATABASE VLDB ADD FILE ( NAME = 'Sales2008_Data', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\Sales2008_Data.ndf', SIZE = 300, FILEGROWTH = 10% ) TO FILEGROUP Sales2008FG GO
In each file group we create a Partitioned View which subdivides the data into 4 separate tables for each quarter (Q1, Q2, Q3, Q4). The following listing shows how to setup the Partitioned View for the 2007 sales data.
-- Table for 2007 Q1 CREATE TABLE [Sales2007_Q1] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2007Q1 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20070101' AND DateKey < '20070401'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2007_Q1] ADD CONSTRAINT PK_Sales2007Q1 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2007/Q1 INSERT INTO [Sales2007_Q1] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20070101' AND DateKey < '20070401' GO -- Table for 2007 Q2 CREATE TABLE [Sales2007_Q2] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2007Q2 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20070401' AND DateKey < '20070701'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2007_Q2] ADD CONSTRAINT PK_Sales2007Q2 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2007/Q2 INSERT INTO [Sales2007_Q2] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20070401' AND DateKey < '20070701' GO -- Table for 2007 Q3 CREATE TABLE [Sales2007_Q3] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2007Q3 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20070701' AND DateKey < '20071001'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2007_Q3] ADD CONSTRAINT PK_Sales2007Q3 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2007/Q3 INSERT INTO [Sales2007_Q3] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20070701' AND DateKey < '20071001' GO -- Table for 2007 Q4 CREATE TABLE [Sales2007_Q4] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2007Q4 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20071001' AND DateKey < '20080101'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2007_Q4] ADD CONSTRAINT PK_Sales2007Q4 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2007/Q4 INSERT INTO [Sales2007_Q4] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20071001' AND DateKey < '20080101' GO -- Create the Partitioned View for 2007 CREATE VIEW Sales2007 AS SELECT * FROM Sales2007_Q1 UNION ALL SELECT * FROM Sales2007_Q2 UNION ALL SELECT * FROM Sales2007_Q3 UNION ALL SELECT * FROM Sales2007_Q4 GO
As you can see from the listing, each individual table has a corresponding CHECK constraint, so that SQL Server can eliminate the tables which don't have to be accessed, when we query our Partitioned View. The next listing shows how to setup the Partitioned View for the 2008 sales data.
-- Table for 2008 Q1 CREATE TABLE [Sales2008_Q1] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2008Q1 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20080101' AND DateKey < '20080401'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2008_Q1] ADD CONSTRAINT PK_Sales2008Q1 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2007/Q1 INSERT INTO [Sales2008_Q1] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20080101' AND DateKey < '20080401' GO -- Table for 2008 Q2 CREATE TABLE [Sales2008_Q2] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2008Q2 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20080401' AND DateKey < '20080701'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2008_Q2] ADD CONSTRAINT PK_Sales2008Q2 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2008/Q2 INSERT INTO [Sales2008_Q2] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20080401' AND DateKey < '20080701' GO -- Table for 2008 Q3 CREATE TABLE [Sales2008_Q3] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2008Q3 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20080701' AND DateKey < '20081001'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2008_Q3] ADD CONSTRAINT PK_Sales2008Q3 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2008/Q3 INSERT INTO [Sales2008_Q3] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20080701' AND DateKey < '20081001' GO -- Table for 2008 Q4 CREATE TABLE [Sales2008_Q4] ( DateKey DATETIME NOT NULL CONSTRAINT Sales2008Q4 -- The CHECK constraint is still needed to do Partition Elimination for the Partitioned View CHECK (DateKey >= '20081001' AND DateKey < '20090101'), OnlineSalesKey INT NOT NULL, SalesOrderNumber NVARCHAR(20) NOT NULL, SalesAmount MONEY NOT NULL ) GO -- Add a primary key clustered ALTER TABLE [Sales2008_Q4] ADD CONSTRAINT PK_Sales2008Q4 PRIMARY KEY CLUSTERED ( DateKey, OnlineSalesKey ) GO -- Load data into the table for the year 2008/Q4 INSERT INTO [Sales2008_Q4] (DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount) SELECT DateKey, OnlineSalesKey, SalesOrderNumber, SalesAmount FROM ContosoRetailDW.dbo.FactOnlineSales WHERE DateKey >= '20081001' AND DateKey < '20090101' GO -- Create the Partitioned View for 2008 CREATE VIEW Sales2008 AS SELECT * FROM Sales2008_Q1 UNION ALL SELECT * FROM Sales2008_Q2 UNION ALL SELECT * FROM Sales2008_Q3 UNION ALL SELECT * FROM Sales2008_Q4 GO
After we have now setup the Partitioned Views for 2007 and 2008, we finally create another Partitioned View which just unions the data of the other 2 Partitioned Views together:
-- Create a Partitioned View on top of the 2 Partitioned Views CREATE VIEW Sales AS SELECT * FROM Sales2007 UNION ALL SELECT * FROM Sales2008 GO
So now we have created our Nested Partitioned View: Partitioned Views within Partitioned Views. The final thing that we now have to check is, if SQL Server is able to do Table Elimination with our Nested Partitioned View. When we talk about Table Elimination (or Partition Elimination with Partitioned Table) we have to differentiate between 2 types of elimination:
- Static Elimination
- Dynamic Elimination
Static Elimination means that you provide within your query a static value. So during the compilation of the Execution Plan the Query Optimizer already knows which data we are accessing. In that case SQL Server generates an Execution Plan, which only references the relevant data. Look at the following query:
-- Shows static Table Elimination across the Partitioned View. -- This SELECT accesses the following table: -- => Sales2007_Q3 SELECT * FROM Sales WHERE DateKey >= '20070721' AND DateKey <= '20070725' GO
We are providing here hard coded values, so the Query Optimizer can sniff them, and generates an Execution Plan, which only accesses the Sales2007_Q3 table. So Static Elimination works without any problems with Nested Partitioned Views, as you can see it in the following Execution Plan:
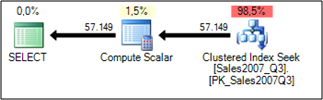
Static Elimination is fine, if you are doing demos etc., but in a production database when you are calling your query with different values through parameters, SQL Server has to do Dynamic Elimination. Dynamic Elimination means that the Query Optimizer has to generate an Execution Plan, which can't take into account during the compilation which tables you are accessing, because those tables are just determined during runtime – therefore the name Dynamic Elimination. So let's imagine we are executing the following parameterized query:
DECLARE @from DATETIME = '20070721' DECLARE @to DATETIME = '20070725' SELECT * FROM Sales WHERE DateKey >= @from AND DateKey <= @to GO
In that case SQL Server can't determine which data is accessed, because the referenced variables are runtime constructs, they are not available during the compilation phase of our query. The above query produces the following Execution Plan:
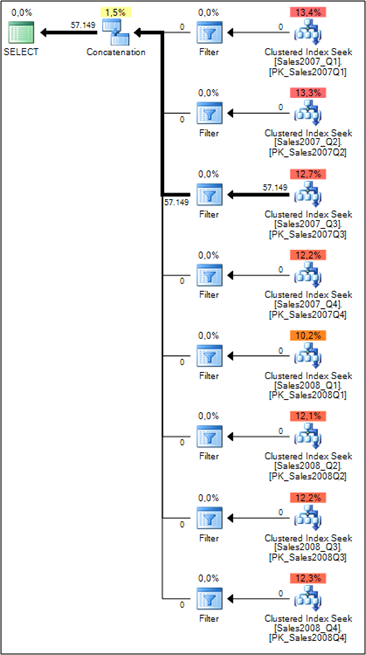
When you look at the first step on that plan, you might think that SQL Server has to seek into each table to get the corresponding records. The Query Optimizer estimates each Clustered Index Seek with around 12%. But that's only the half-truth of that Execution Plan! The real power lies in the Filter Operator which comes before the Clustered Index Seek. When you look at the Tooltip Window of the Filter Operator inside SQL Server Management Studio, you can see that the operator has a so-called Startup Expression Predicate:
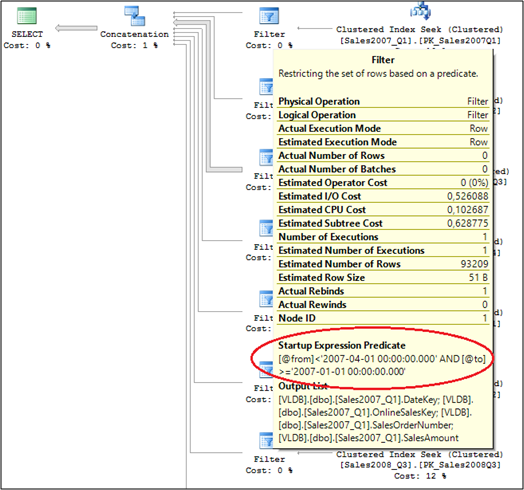
As you can see from the picture, the Startup Expression Predicate has the same value as the CHECK constraint on the table itself. So that Filter Operator only calls the Clustered Index Seek operator on the underlying table when the Startup Expression Predicate is evaluated to true! You can also cross-check this with the property Actual Executions on the Clustered Index Seek Operators:
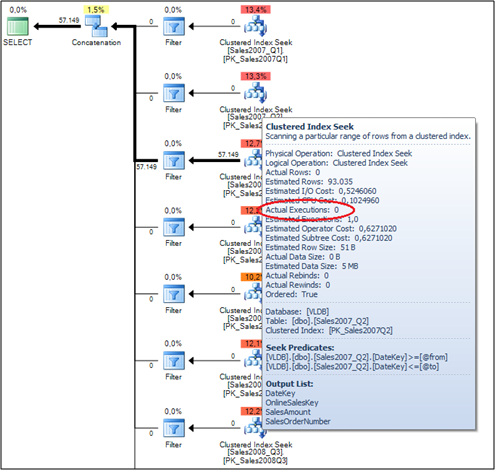
In our case SQL Server only executed the Clustered Index Seek Operator on the Sales2007_Q3 table. On all other tables the Filter Operator prevented through the Startup Expression Predicate the execution of the Clustered Index Seeks! That's a really powerful concept for Dynamic Table Elimination inside Partitioned Views.
As you can see from this example, Nested Partitioned Views are working without any problems in SQL Server, and on the other hand SQL Server uses a Startup Expression Predicate inside a Filter Operator to drive Dynamic Table Elimination when you work with Partitioned Views – it doesn't matter here if those Views are nested or not. In that case it is really important that you check the whole Execution Plan to get a better understanding what SQL Server is actually doing for your query. When you just look on that plan (without going into the details), you might think that SQL Server has to access every table, but that's not really true!
A big Thank You goes to Paul White (Weblog, Twitter) who helped me to understand that behavior and implementation strategy of SQL Server.
Thanks for reading
-Klaus
3 thoughts on “Nested Partitioned Views”
Hi Klaus,
Thanks fot the nice article! It’s great that SQL Server optimizer did not touch all tables by using check constraints info in a partitioned view. This is not the case in a singe table. For instance SELECT * FROM Sales2007_Q1 WHERE DateKey>’20080101′; will be executed without touching the Sales2007_Q1 table, but DECLARE @D DATE=’20080101′; SELECT * FROM Sales2007_Q1 WHERE DateKey>@D; would touch the table (there is no Filter operator).
You can use OPTION(RECOMPILE) hint and "postpone" the execution plan considerations and then SQL Server works with variables in the same manner as with literals. Of course, the statement will be recompiled each time and this could be significant costs.
It is good to know that using variables against partitioned views does not bring performance problems although the execution plan looks database consulting friendly 🙂
Thanks for sharing experience.
Regards,
Milos
Great 🙂
Wow!!!
If only something like this was possibile with SSAS Standard…
Thank you for the article.
Comments are closed.