In the last weeks and months I have prepared tons of SQL Server 2012 content for my own SQL Server 2012 Deep Dive Days workshop that I’m currently running across Europe. Because this content shows in a very good way how you can use all the various new features of SQL Server 2012, I have decided to share over the year some of that content through my weblog. Today I want to start with SQL Server 2012 AlwaysOn Availability Groups, because that’s one of the hottest features in SQL Server 2012!
I want to take you from a zero knowledge level and show you step by step how you can configure, deploy, and manage a SQL Server 2012 AlwaysOn High Availability solution. In today’s first part I want to talk about the basic architecture of AlwaysOn and how you can prepare SQL Server for running an AlwaysOn solution.
Overview
AlwaysOn Availability Groups is the big new feature in the High Availability stack of SQL Server 2012. Simply said it is the successor of Database Mirroring that was introduced with SQL Server 2005 SP1. Database Mirroring is a great technology for achieving HA (High Availability) and DR (Disaster Recovery), but has some weaknesses and limitations:
- You can only mirror 1 database through a Database Mirroring session. When you have an application that consists of several database (just think of SharePoint Server), then you need to have several distinct Mirroring sessions.
- The Failover is done on the Mirroring session level, which means you can only failover 1 database at a given time. Again – if you have more than 1 database, you need different Mirroring sessions and you have to coordinate a multi-database failover at your own.
- There is only 1 Mirroring partner possible. You can’t mirror to different partners. The Mirroring partner can be run with Synchronous Commit for achieving High Availability or with Asynchronous Commit for achieving Disaster Recovery. If you are using Synchronous Commit you can get an Automatic Failover if you deploy a Witness instance. This witness instance is used for acquiring a quorum and avoiding a so-called Split-Brain scenario.
- The Mirroring database is always replaying Transaction Log records, which means that you are not able to access the database for read-only access (the undo part of Recovery has not yet run). The only possibility is to use Database Snapshots to get a consistent view of your database at a given point in time and refresh the Database Snapshot on a regularly basis, but again – you have to do this at your own.
Beginning with SQL Server 2012 Microsoft provides us now AlwaysOn Availability Groups which are the successor of Database Mirroring.
Side Note: Database Mirroring is still available in its original feature set, but it is marked as a Deprecated Feature, which means, that it will be removed in a future release of SQL Server.
AlwaysOn Availability Groups offers you the following advantages over traditional Database Mirroring:
- Multi-Database Failovers
- Multiple Secondaries
- Active Secondaries
- Integrated HA Management
The following figure gives you a basic overview about AlwaysOn Availability Groups.
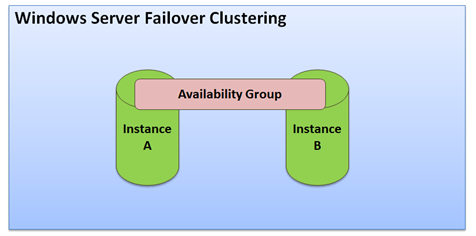
As you can see from the previous figure, an AlwaysOn Availability Group is created between several standalone SQL Server instances. At least you need 2 different SQL Server instances. All instances that participating in an AlwaysOn Availability Group don’t need any Shared Storage – each SQL Server instance has its own local storage. It’s the same concept as with Database Mirroring. The only requirement is the fact that each participating SQL Server instance must be in the same Windows Domain, because you must create a Windows Server Failover Cluster (WSFC) that contains all participating SQL Server Instances. SQL Server uses underneath several WSFC features like the Quorum Model. Database Mirroring uses its own Quorum Model by using a dedicated Witness instance.
Side Note: In my opinion this one of the biggest disadvantages of AlwaysOn Availability Groups. I have a few customers which wanted to migrate from Database Mirroring to Availability Groups, but they can’t go that direction at this time, because their SQL Server instances are not in the same domain. Some even have deployed SQL Server instances in separate workgroups… But that’s the way how AlwaysOn Availability Groups are working, and that’s the price that you have to pay for that new feature.
An Availability Group itself can contain several databases, which can failover in a whole set – that’s a huge difference and improvement compared to Database Mirroring. Each participating SQL Server instance hosts a so-called Replica. There is always one Primary Replica and up to four Secondary Replicas. Up to 2 of these Secondary Replicas can use Synchronous Commit, and the other 2 Secondary Replicas can use Asynchronous Commit. When you run 2 Replicas with Synchronous Commit you can also configure an Automatic Failover between them. They are forming a so-called “Automatic Failover Pair”.
Another big advantage of the Secondaries is that they are readable. You don’t need a Database Snapshot anymore, as you would have done it with Database Mirroring. But you must be aware that there is an overhead when you are using Active Secondaries – but we will look into that topic in more detail at a later stage of this weblog series. You can also use Active Secondaries for doing backup jobs, which will be also a very nice way to move backup workload away from your Primary Replica.
As with Database Mirroring, Transaction Log records are transferred from one Replica to the others. To minimize network latency, SQL Server 2012 uses Build in Log Compression to transfer Transaction Log records as fast as possible.
Preparing your SQL Server for AlwaysOn
If you want to deploy an Availability Group solution you have to prepare your SQL Server instances in the first step. For this weblog posting I’m assuming that you have setup 5 different SQL Server installations across 5 physical servers/Virtual Machines. As an Operating System I’m assuming Windows Server 2008 R2 SP1 x64. My current Hyper-V based deployment looks like the following:
-
Node1
- DNS Name: ag-node1.sqlpassion.com
- IP Address: 192.168.1.211
- SQL Service Account: ag_node1_sqlsvc@sqlpassion.com
-
Node 2
- DNS Name: ag-node2.sqlpassion.com
- IP Address: 192.168.1.212
- SQL Service Account: ag_node2_sqlsvc@sqlpassion.com
-
Node 3
- DNS Name: ag-node3.sqlpassion.com
- IP Address: 192.168.1.213
- SQL Service Account: ag_node3_sqlsvc@sqlpassion.com
-
Node 4
- DNS Name: ag-node4.sqlpassion.com
- IP Address: 192.168.1.214
- SQL Service Account: ag_node4_sqlsvc@sqlpassion.com
-
Node 5
- DNS Name: ag-node5.sqlpassion.com
- IP Address: 192.168.1.215
- SQL Service Account: ag_node5_sqlsvc@sqlpassion.com
Each VM node is also part of my sqlpassion.com Windows domain, and I have performed a default SQL Server 2012 installation with a default instance of SQL Server 2012. Furthermore each SQL Server default instance uses a Windows Domain account for the SQL Server Service Account. You must also make sure during the installation that you place your MDF/LDF files on the same physical location on each VM node, otherwise you will run into troubles with the wizards provided by AlwaysOn Availability Groups.
The first step that you have to perform is the creation of a new Windows Server Failover Cluster (WSFC). In the first step this sounds like a huge step, but it is very easy to do because you don’t need any shared storage. One prerequisite of WSFC is the fact that you have to install the Failover Cluster Feature on each node. You can perform this task through the Server Manager of Windows Server 2008 R2.
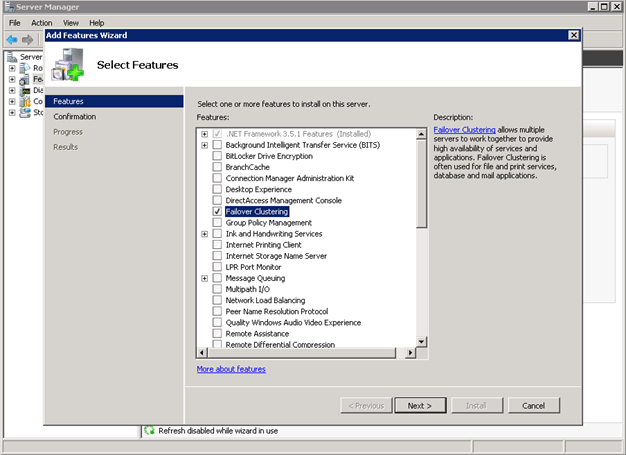
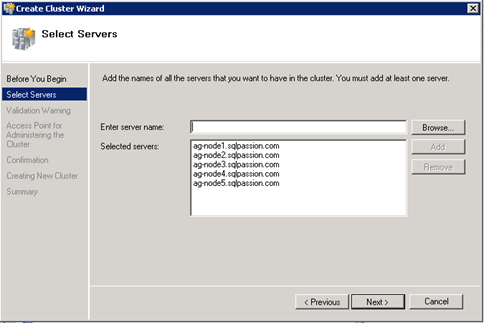
After you have installed the Failover Clustering on EACH node, you have to log into one of these nodes through a Windows Domain user account. Otherwise you are not able to create the Windows Server Failover Cluster itself. To create the cluster itself you can use the Failover Cluster Manager, which can be found in the Administrative Tools of your Control Panel. On the right hand side you can see all available Actions, and here you choose the option “Create a Cluster…“. In the first step the wizard asks you which nodes should be part of the new WSFC Cluster. In my case I have selected all 5 VM nodes:
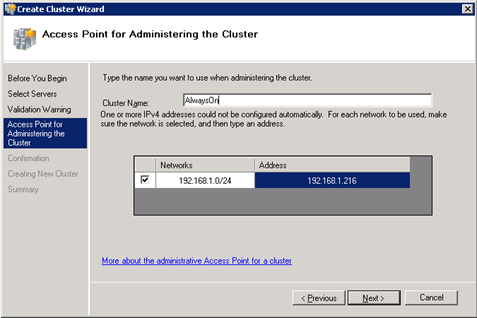
On the next wizard page you have to choose to run the Cluster Configuration Validation Tests. If you want to get support from Microsoft, you have to run them. For AlwaysOn Availability Groups you don’t have to include the tests regarding shared storage, because you are not using any form of shared storage for an Availability Group. After you have run your Cluster Configuration Validation Tests, you have to give your WSFC Cluster a name and an IP address:
With all these information in the hand, the wizard will finally create your WSFC cluster. After the successful creation you can see your new WSFC cluster in the Failover Cluster Manager:
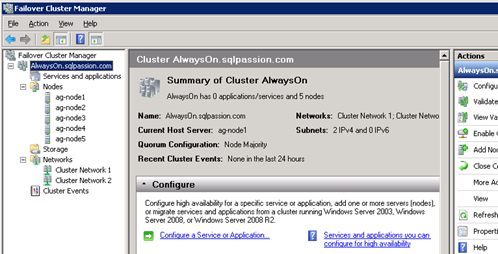
As you can see from the previous figure, the Cluster is currently not hosting any Service or an Application yet. We just have created the skeleton so that an AlwaysOn Availability Group can be created and deployed. In the final step you have now to enable AlwaysOn Availability Groups on each SQL Server instance. This can be done through the SQL Server Configuration Manager and the tab AlwaysOn High Availability. You have to enable the checkbox “Enable AlwaysOn Availability Groups“. This option is only available when the computer where the SQL Server instance is running on, is part of a WSFC cluster:
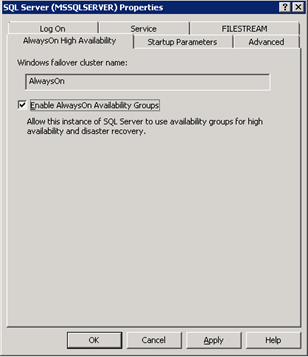
After you have enabled that option, you must restart your SQL Server instance. Please make sure to do this configuration change on EACH node that is part of your WSFC cluster.
By now we have created the whole infrastructure that is necessary to run a SQL Server 2012 AlwaysOn Availability Group solution. In the next weblog posting you will then see, how you can deploy your first Availability Group with SQL Server 2012.
If you are interested in SQL Server 2012, I suggest looking on my “SQL Server 2012 Deep Dive Days Workshop”, which I run from May 28 – 30 in London/United Kingdom (see http://www.SQLpassion.at/academy, Early Bird price ends on March 31). This workshop was already running in Vienna/Austria and Munich/Germany with a huge success.
Stay tuned J
-Klaus
4 thoughts on “SQL Server 2012 AlwaysOn Availability Groups – Part 1”
thanks not many people have blogged about Hadron setup yet. very useful post
This was a great help for building my first SQL12 AlwaysOn Availability group – Nice and precise. I am looking forward to reading the next post(s) of this author (Klaus A.)
Great writeup. Looking forward to Part 2 for how to setup the databases once the servers are installed and AAG-capable.
I was able to cluster the servers prior to installing SQL individually, and that doesn’t seem to have hurt anything.
Also, when installing SQL, you must apparently opt for the standalone installation for each node, rather than the cluster installation. The former lets you use local database storage on each node, and the latter implies that you will use a shared disk of some sort.
Very good article. Gives depth knowledge in simple language. Keep it up.
Comments are closed.