Today I want to talk about Statistics Enhancements in SQL Server 2012. As you already know SQL Server uses Statistic Objects in a database to estimate the cardinality of queries. The cardinality estimation is the input for the generation of the physical Execution Plan of a given T-SQL query. Data changes over time, data distribution changes over time, so SQL Server is also able to change Statistics Objects in the background automatically for us. This feature is called Auto Update Statistics. SQL Server updates Statistics automatically under the following conditions (when the table is not a temp table):
- A table with no rows gets a row
- A table has fewer than 500 rows and is increased by 500 or more rows
- A table has more than 500 rows and is increased by 500 rows + 20 percent of the number of rows
Whenever SQL Server is updating the statistics automatically, SQL Server Profiler reports the Auto Stats event. On the other hand, SQL Server is also able to create Statistic Objects on the fly, when SQL Server needs to estimate the cardinality for a given query and no index (and therefore no Statistics Object) is available, like in the following one:
SELECT * FROM Table1 WHERE Column1 > 1 GO
When Column1 is not indexed, SQL Server will create a new Statistics Object for you.
All these things are great to improve performance for queries, but what happens when SQL Server can’t change the underlying Statistics Object or isn’t able to create a new one for you? Just think of databases that are marked as read only, or when you are using Database Snapshots. Data in Database Snapshots can’t change, but you can issue completely new queries that leads to the demand of creating new Statistics Objects.
In that case, SQL Server can’t create/update the Statistics Object, which means SQL Server can’t re-evaluate the cardinality estimation and proceeds with the cached execution plan, which can have a huge performance drawback for your read only workload. Let’s demonstrate this problem with a simple example. I’m creating a new database with a simple table in it:
USE master GO CREATE DATABASE StatisticsDatabase GO USE StatisticsDatabase GO CREATE TABLE Table1 ( Column1 INT IDENTITY, Column2 INT ) GO
In the next step I’m populating the table with 1500 records:
SELECT TOP 1500 IDENTITY(INT, 1, 1) AS n INTO #Nums FROM master.dbo.syscolumns sc1 INSERT INTO Table1 (Column2) SELECT n FROM #nums DROP TABLE #nums GO
When we select everything from the table, SQL Server uses the Table Scan operator, because we have not defined a Clustered Index on our table:
SELECT * FROM Table1 GO
To demonstrate the problem with errors in the cardinality estimation I’m creating a Non-Clustered Index on Column2.
CREATE NONCLUSTERED INDEX idxTable1_Column2 ON Table1(Column2) GO
The following query uses the previous created Non-Clustered Index:
SELECT * FROM Table1 WHERE Column2 = 2 GO
SQL Server creates an Execution Plan with a Non-Clustered Index Seek and RID Lookup (Heap) operator – the traditional Bookmark Lookup operator. By now we have a table with 1500 records, which means we need 20 percent + 500 rows of data changes, until SQL Server will update the underlying Statistics Object of the Non-Clustered Index. In our case these are 800 data changes in our table (300 + 500). So let’s insert 800 additional records into the table:
SELECT TOP 800 IDENTITY(INT, 1, 1) AS n INTO #Nums FROM master.dbo.syscolumns sc1 INSERT INTO Table1 (Column2) SELECT 2 FROM #nums DROP TABLE #nums GO
SQL Server will update the Statistics Object as soon as a new SELECT query will reference it. Prior to that we will now mark our database as read only, so that SQL Server can’t change anything anymore:
USE master GO -- Mark the database as readonly ALTER DATABASE StatisticsDatabase SET READ_ONLY WITH NO_WAIT GO USE StatisticsDatabase GO
Let’s now run the query which will trigger an update of the Statistics Object:
SELECT * FROM Table1 WHERE Column2 = 2 GO
Under normal conditions, SQL Server will now re-evaluate the cardinality estimation and create an Execution Plan with a Table Scan operator. But in our case SQL Server can’t change anything in the database, therefore SQL Server will reuse the inefficient cached Execution Plan with the Bookmark Lookup! When you look at the Execution Plan you will also see a huge difference between the Estimated and Actual Number of Rows:
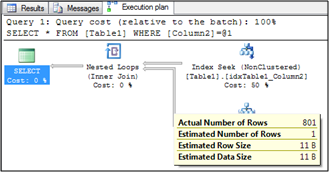
That’s the behavior of SQL Server 2005/2008 (R2), and you can’t change anything about it. The same problem will occur when you are using Database Snapshots.
But with SQL Server 2012 Microsoft has addressed that problem. SQL Server now supports so-called Temporary Statistic Objects which are created in TempDb. Every time when SQL Server wants to create or update an Statistics Object on a read only database or on a Database Snapshot, SQL Server will create the necessary Statistics Object in TempDb. For this functionality SQL Server needs 1 data page per each Statistics Object in TempDb.
So when you run the previous code on SQL Server 2012, SQL Server will create a new temporary Statistics Object in TempDb, and will create an Execution Plan with a Table Scan operator, which makes much more sense, because our query is not selective enough anymore.
Temporary Statistics Objects are also used by Readable Secondaries in AlwaysOn in SQL Server 2012, because Readable Secondaries also have the same problem: they are used for read only workloads, and SQL Server can’t change anything in the Secondary Replica, because all Replicas must have the same physical structure in the Availability Group. So every time when you are working with readable Secondaries in SQL Server 2012, you will also have an overhead in TempDb, because of temporary Statistics. And Readable Secondaries are also using transparently Snapshot Isolation, which also impacts the performance of TempDb. But that’s a topic for another weblog posting J.
Thanks for reading!
-Klaus
2 thoughts on “Statistics Enhancements in SQL Server 2012”
Certainly a useful feature for read-only sites, although tempdb size and usage needs to be take care of cautiously while using availability groups. Thanks for sharing. Keep going..
Alias is useful only if you’re deliang with complex queries involving multiple tables; specially if you run the risk of 2 different tables having the same or similar field names.
Comments are closed.