Almost everytime when I’m doing SQL Server consulting engagements, DBAs are showing me queries and their Execution Plans, where SQL Server is just ignoring a good defined Non-Clustered Index. Imagine for example the following table and index definition:
CREATE TABLE Customers ( CustomerID INT NOT NULL, CustomerName CHAR(100) NOT NULL, CustomerAddress CHAR(100) NOT NULL, Comments CHAR(185) NOT NULL, Value INT NOT NULL ) GO CREATE UNIQUE CLUSTERED INDEX idx_Customers ON Customers(CustomerID) GO CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value) GO
When you are populating the table with 80.000 records and running the following query, SQL Server just ignores your Non-Clustered Index and scans the whole table:
SELECT * FROM Customers WHERE Value < 1063 GO
Mostly people are now proud, because they think they have found a bug in SQL Server, and sometimes they are trying to hint the Query Optimizer with an index hint, which then produces the following (expected) Execution Plan:
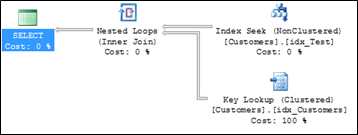
As you can see from the picture, SQL Server has to do a Bookmark Lookup, because you don't have a Covering Non-Clustered Index defined for that specific query. SQL Server is doing you here a big favor, when your whole Clustered Index is scanned: making the Bookmark Lookup for every retrieved record is too expensive, so SQL Server scans the whole table, which produces less I/Os for your query and reduces the CPU consumption, because the Bookmark Lookup is always done through a Nested Loop operator.
This behavior or "safety net" is called the Tipping Point in SQL Server. Let's have now a more detailed look on that concept. In a short, the Tipping Point just defines if SQL Server is doing a Bookmark Lookup, or a whole Table/Clustered Index Scan. This also implies that the Tipping Point is only relevant for Non-Covering Non-Clustered Indexes. An index which acts as a Covering Non-Clustered Index for a specific query doesn't have a Tipping Point, so the problems described in this blog posting are not relevant to it.
When you have a specific query in front of you, which produces a Bookmark Lookup, it depends on the number of retrieved pages if SQL Server is doing a full scan or using the Bookmark Lookup. Yes, you have read correct: the number of retrieved pages dictates if it's good or not good to do a Bookmark Lookup! Therefore it is completely *irrelevant* how many records a specific query returns, the only thing that matters is the number of pages. The Tipping Point is somewhere between 24% - 33% of the pages the query has to read for a specific query.
Before that range, the Query Optimizer chooses a Bookmark Lookup, after the query tipped over, the Query Optimizer produces an Execution Plan with a full scan of the table (with a Predicate inside the Scan operator). This also means that the size of your records defines where the Tipping Point lives. With very small records you can only retrieve a smaller set of records from your table, with larger records you can retrieve a huger set of records, before the query is over the Tipping Point and is doing a full scan. The following picture illustrates this behavior in more detail:

Let's have a look on some concrete examples of that concept. Let's just populate the table definition from earlier with 80.000 records:
DECLARE @i INT = 1 WHILE (@i <= 80000) BEGIN INSERT INTO Customers VALUES ( @i, 'CustomerName' + CAST(@i AS CHAR), 'CustomerAddress' + CAST(@i AS CHAR), 'Comments' + CAST(@i AS CHAR), @i ) SET @i += 1 END GO
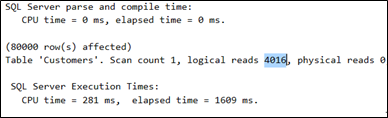
In our case every record is 400 bytes long, therefore 20 records can be stored on 1 page of 8kb. When we are doing a full scan (SELECT * FROM Customers) of the table, SQL Server produces 4.016 logical reads (can be seen from the session option SET STATISTICS IO ON):
In our case the table consists of 4.000 data pages in the leaf level of the Clustered Index, which means the Tipping Point is somewhere between 1.000 and 1.333 pages that we are reading for that specific table. This means you can read about 1,25% - 1,67% (1000/80000, 1333/80000) of the records from the table, before the Query Optimizer decides to do a full scan of the table. Imagine the following query:
SELECT * FROM Customers WHERE Value < 1062 GO
In that case SQL Server decides to do a Bookmark Lookup, because the query itself produces 3.262 logical reads. Imagine that: you are retrieving 1.061 records out of 80.000 records, and the query already needs 3.262 logical reads – a complete scan of the table just costs you constantly 4.016 logical reads (regardless of the number of records that the query returns).
As you can see from these numbers, Bookmark Lookups are getting really expensive (regarding I/O costs, and also regarding CPU costs!), when you retrieve a huge amount of records through a Bookmark Lookup. Your logical reads would just explode, and therefore SQL Server implements the Tipping Point, which just discards that inefficient Execution Plan and scans the whole table. Imagine the following almost same query:
SELECT * FROM Customers WHERE Value < 1063 GO
In that case SQL Server discards the Execution Plan with the Bookmark Lookup and is doing a full scan of the table which produces constantly 4.016 logical reads. Almost 2 identical queries, but 2 different Execution Plans! A huge problem for performance tuning, because you have no Plan Stability anymore.
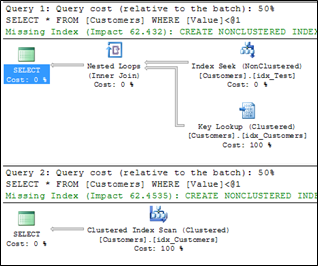
Based on your input parameters you are getting 2 different plans! That's also one of the biggest drawbacks of Bookmark Lookups. With Bookmark Lookups you can't achieve Plan Stability! When such a cached plan get's reused with a huger amount of records (or your statistics are out-of-date), you will really have performance problems, because the inefficient plan with the Bookmark Lookup get's blindly reused by SQL Server! I have seen examples of that problem where queries were running minutes instead of a few seconds.
As we have already said, the Tipping Point depends on the number of pages you read for your specific query. Imagine we are changing our table definition a little bit, and each record is now only 40 bytes long. In that case 200 records can be stored on one page of 8kb.
CREATE TABLE Customers3 ( CustomerID INT NOT NULL, CustomerName CHAR(10) NOT NULL, CustomerAddress CHAR(10) NOT NULL, Comments CHAR(5) NOT NULL, Value INT NOT NULL ) GO
When we are populating the table again with 80.000 records, we need only 400 pages in the leaf level of the Clustered Index. In this case the Tipping Point is somewhere between 100 and 133 read pages, means you can only retrieve around 0,125% - 0,167% of the records through the Non-Clustered Index. This is almost NOTHING! Your Non-Covering Non-Clustered Index is now just useless!!!
The following query produces a Bookmark Lookup, and the second one a Clustered Index Scan:
-- Bookmark Lookup with 332 logical reads, SELECT * FROM Customers3 WHERE Value < 157 GO -- The following query does a clustered index scan. -- The query produces 419 I/Os. SELECT * FROM Customers3 WHERE Value < 158 GO
As you can see from the second query, you only retrieve 157 records out of 80.000 records, which means your query is very, very, very selective, but SQL Server just ignores your perfect (?) Non-Clustered Index. For that query your Non-Clustered Index isn't really perfect, because it's not a Covering Non-Clustered Index. Imagine what happens when you hint SQL Server for the Non-Clustered Index, and you just retrieve every record from the table through the ineffient Bookmark Lookup:
SELECT * FROM Customers3 WITH(INDEX(idx_Test)) WHERE Value < 80001 GO
That query produces 165.151 logical reads – really far away from the logical reads that the Clustered Index Scan produces. As you can see from this example, the Tipping Point is just a safety net in SQL Server, and prevents that queries with a Bookmark Lookup get really expensive. But it doesn't depend on the number of records. In both examples we dealed with the same amount of records in the table – 80.000. The only thing that we have changed is the size of the records, and therefore we have changed the size of the table, and finally the Tipping Point changed, and SQL Server just ignored our almost perfect Non-Clustered Index.
Moral of the story: a Non-Clustered Index, which isn't a Covering Non-Clustered Index has a very, very, very, very, very selective Use Case in SQL Server! Think about that the next time when you are working on your indexing strategy.
Call to action: do you have also encountered in your workloads scenarios where SQL Server just ignored your almost perfect Non-Clustered Index, and you thought about what is going on with that specific query? Please feel free to leave a comment with your stories...
Thanks for reading
-Klaus