During the last days I’m working on Replication – especially with Transactional Replication. The main idea of Transactional Replication is that you have a so-called Log Reader Agent on your Publisher SQL Server database running, that is analyzing the Transaction Log File and synchronize changes on so-called Articles through a Distribution database down to your Subscription databases.
When you setup your Transactional Replication through SQL Server Management Studio, you can only initialize the Subscription database through a so-called Snapshot. A snapshot is just a point-in-time “picture” of your database, which is dumped out to a file share through bcp.exe. Imagine now that you want to publish parts of a VLDB (Very Large Database) to various Subscribers. In that case Transactional Replication must make a snapshot on the Articles that you want to replicate from your VLDB. That’s not very practical, because it can take a very long time to make that snapshot and initialize the Subscribers from that snapshot.
Fortunately there is also an option to initialize a Subscriber from a backup file, but unfortunately this option isn’t available through SQL Server Management Studio – you have to choose that option through the Replication Stored Procedures that are used in the background by SQL Server to implement the actual Replication. The idea of initializing a Transactional Replication from a backup file is not very new, because there are also other blog postings on this topic, but I wasn’t able to find a step-by-step tutorial how to implement this approach. The most important blog posting is from Chris Skorlinski (http://blogs.msdn.com/b/repltalk/archive/2010/03/16/deep-dive-on-initialize-from-backup-for-transactional-replication.aspx). With the information provided in that posting I was finally able to do the initialization from a backup file. In this blog posting I want to show you now step-by-step how you can achieve that functionality.
In my distributed scenario Transactional Replication is running on 3 different VMs:
- SQL2008HADR1: Publisher
- SQL2008HADR2: Distributor
- SQL2008HADR3: Subscriber
Running Replication in a fully distributed scenario is more realistic, but the setup of the needed security is also a topic on its own. Fortunately Joe Sack from SQLskills.com has written a few weeks ago a very nice article how to setup security – see http://www.sqlskills.com/blogs/joe/post/SQL-Server-Pro-articlee28093e2809cGetting-Started-with-Transactional-Replicatione2809d.aspx for further details on that.
To get started I have created a completely new database on SQL2008HADR1 which acts as the Publisher for Transactional Replication:
USE master
GO
-- Create a new database that we want to use with Transactional Replication
CREATE DATABASE PublisherDatabase
GO
USE PublisherDatabase
GO
-- Create a new table that we want to replicate
CREATE TABLE Foo
(
Col1 INT IDENTITY(1, 1) PRIMARY KEY NOT NULL,
Col2 CHAR(1000) NOT NULL,
Col3 CHAR(1000) NOT NULL
)
GO
-- Insert 1000 records
INSERT INTO Foo VALUES ('xyz', 'xyz')
GO 1000
-- Retrieve the inserted records
SELECT * FROM Foo
GO
-- Make a initial full database backup
BACKUP DATABASE PublisherDatabase TO DISK = '\\dc\temp\PublisherDatabase.bak'
GO
-- Insert another 1000 records
INSERT INTO Foo VALUES ('xyz', 'xyz')
GO 1000
-- Retrieve the inserted records.
-- The last 1000 records are not part of the initial full database backup.
SELECT * FROM Foo
GO
As you can see from the code, I have created a simple table called Foo, and inserted several records into that table. I have also created a full database backup and afterwards I have inserted several other records, which are currently stored in no backup. In the next step you have to create your Publication on the Publisher. This can be done completely through the UI provided by SQL Server Management Studio. The only thing that you don’t have to do is the creation of an initial snapshot, because we don’t need that snapshot.
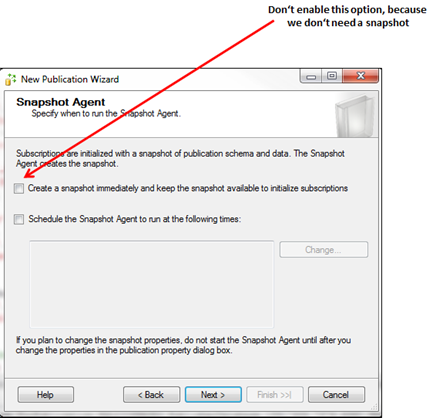
In my case I have scripted out the creation of the Publication, which resulted in the following T-SQL code:
USE PublisherDatabase GO EXEC sp_replicationdboption @dbname = N'PublisherDatabase', @optname = N'publish', @value = N'true' GO -- Adding the transactional publication EXEC sp_addpublication @publication = N'FooPublication', @description = N'Transactional publication of database ''PublisherDatabase'' from Publisher ''SQL2008HADR1''.', @sync_method = N'concurrent', @retention = 0, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'false', @enabled_for_internet = N'false', @snapshot_in_defaultfolder = N'true', @compress_snapshot = N'false', @ftp_port = 21, @allow_subscription_copy = N'false', @add_to_active_directory = N'false', @repl_freq = N'continuous', @status = N'active', @independent_agent = N'true', @immediate_sync = N'false', @allow_sync_tran = N'false', @allow_queued_tran = N'false', @allow_dts = N'false', @replicate_ddl = 1, @allow_initialize_from_backup = N'false', @enabled_for_p2p = N'false', @enabled_for_het_sub = N'false' GO -- Add the Snapshot Agent for the Publication EXEC sp_addpublication_snapshot @publication = N'FooPublication', @frequency_type = 1, @frequency_interval = 1, @frequency_relative_interval = 1, @frequency_recurrence_factor = 0, @frequency_subday = 8, @frequency_subday_interval = 1, @active_start_time_of_day = 0, @active_end_time_of_day = 235959, @active_start_date = 0, @active_end_date = 0, @job_login = null, @job_password = null, @publisher_security_mode = 1 GO -- Add an Article to the Publication EXEC sp_addarticle @publication = N'FooPublication', @article = N'Foo', @source_owner = N'dbo', @source_object = N'Foo', @type = N'logbased', @description = null, @creation_script = null, @pre_creation_cmd = N'drop', @schema_option = 0x000000000803509F, @identityrangemanagementoption = N'manual', @destination_table = N'Foo', @destination_owner = N'dbo', @vertical_partition = N'false', @ins_cmd = N'CALL sp_MSins_dboFoo', @del_cmd = N'CALL sp_MSdel_dboFoo', @upd_cmd = N'SCALL sp_MSupd_dboFoo' GO
In that publication I’m just replicating the whole table Foo. I have not applied any filter. After you have created your Publication, you must change one setting through the UI of SQL Server Management Studio. I was not able to figure it out, if this change can be also done through T-SQL. You have to allow the initialization from backup files for subscribers. To change that setting you are doing to the local publication on the Publisher, then you go to the Properties-Window, and finally to the page “Subscription Options“. And here you are setting the option “Allow initialization from backup files” to “True“.
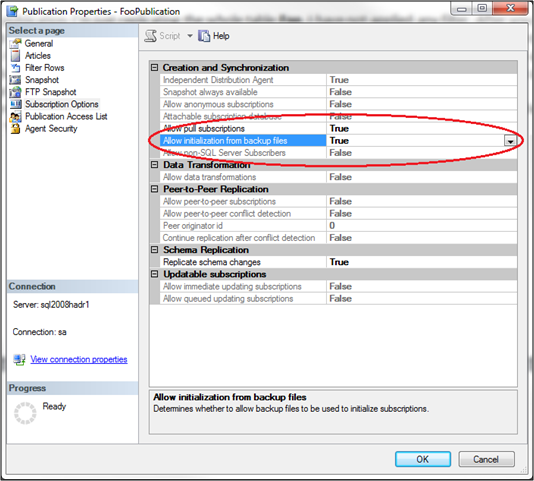
This setting allows the Subscribers to be initialized by a backup. In the next step I’m making a final Transaction Log Backup, so that all transactions are backed up.
Note: You need to do a backup after the Publication was configured on the Publisher. Otherwise the initialization from backup will not work!
-- Create another log backup of the Publisher database. BACKUP LOG PublisherDatabase TO DISK = '\\dc\temp\PublisherDatabase_Tran1.trn' GO
When you are using Replication in a distributed scenario you also have to make sure that the Distribution Agent can access your Publisher database.
In the next step you can restore the taken database backups on the subscriber, in my case SQL2008HADR3.
-- Restore the initial full database backup RESTORE DATABASE PublisherDatabase FROM DISK = '\\dc\temp\PublisherDatabase.bak' WITH NORECOVERY GO -- Restore the last Transaction Log Backup RESTORE DATABASE PublisherDatabase FROM DISK = '\\dc\temp\PublisherDatabase_Tran1.trn' WITH RECOVERY GO
Now you are ready to create the Subscription. When you create a new Subscription you have to make changes on both the Publisher and also on the Subscriber. Therefore you have to execute the following T-SQL code on the Publisher (SQL2008HADR1) to create the Subscription.
USE PublisherDatabase GO -- Add the Subscription on the Publisher EXEC sp_addsubscription @publication = N'FooPublication', @subscriber = N'sql2008hadr3', @destination_db = N'PublisherDatabase', @sync_type = N'initialize with backup', @backupdevicetype='Disk', @backupdevicename='\\dc\temp\PublisherDatabase_Tran1.trn', @subscription_type = N'pull', @update_mode = N'read only' GO
When you are calling the stored procedure sp_addsubscription on the Publisher you can now specify that you want to initialize the Subscribers through a database backup. For that reason you set the parameter @sync_type to “initialize with backup“. You also have to supply the *last* backup that you have restored on the Subscriber through the parameter @backupdevicename. In my case this is the Transaction Log backup that I have done previously. This backup is then opened by sp_addsubscription to get the last LSN (Log Sequence Number) of the backup. This LSN is used by the Distribution Agent to replicate commands from the msrepl_transactions table to the Subscriber that have occurred afterwards.
Note: You have to call sp_addsubscription directly from T-SQL, because setting these options is not possible through SQL Server Management Studio.
When you have created the Subscription on the Publisher, you are finally ready to create it on the Subscriber (SQL2008HADR3).
USE PublisherDatabase GO -- Add the Pull Subscription EXEC sp_addpullsubscription @publisher = N'SQL2008HADR1', @publication = N'FooPublication', @publisher_db = N'PublisherDatabase', @independent_agent = N'True', @subscription_type = N'pull', @description = N'', @update_mode = N'read only', @immediate_sync = 0 GO -- Add the Pull Subscription Agent EXEC sp_addpullsubscription_agent @publisher = N'SQL2008HADR1', @publisher_db = N'PublisherDatabase', @publication = N'FooPublication', @distributor = N'SQL2008HADR2', @distributor_security_mode = 1, @distributor_login = N'', @distributor_password = null, @enabled_for_syncmgr = N'False', @frequency_type = 64, @frequency_interval = 0, @frequency_relative_interval = 0, @frequency_recurrence_factor = 0, @frequency_subday = 0, @frequency_subday_interval = 0, @active_start_time_of_day = 0, @active_end_time_of_day = 235959, @active_start_date = 20120805, @active_end_date = 99991231, @alt_snapshot_folder = N'', @working_directory = N'', @use_ftp = N'False', @job_login = null, @job_password = null, @publication_type = 0 GO
After completing these steps you have a fully working Transactional Replication which was initialized by a database backup instead of a snapshot. For VLDBs this can be a huge advantage instead of creating a very big snapshot that must be transferred over the network to the Subscriber, and finally applied. The drawback of this approach is that you have to restore your whole database on the Subscriber, and not only the Articles that you are publishing. Additionally you also have the whole data on the Subscriber, even when you are replicating Articles with Filter. For these reasons you have to delete the unnecessary data on the Subscriber afterwards manually.
Thanks for reading!
-Klaus