Last Thursday I had the chance to attend the PGDay Austria conference, and it turned out to be one of the most inspiring community events I’ve been to in a long time. Not only did I listen to great talks about PostgreSQL internals, I also gave my very first lightning talk – nervously stepping on stage with the deliberately provocative title: “I cheated on SQL Server – with PostgreSQL.” As someone who has spent more than two decades working with SQL Server, that confession got a lot of smiles from the audience.
Among the many things I took home from the conference was a concept that stuck in my head immediately: Column Tetris. The term was used to describe how the order of columns in a PostgreSQL table can have a real impact on storage size. By reordering columns – much like stacking Tetris blocks to avoid gaps – you can minimize wasted space caused by PostgreSQL’s strict alignment rules.

That idea made me think deeply about migrations. Why is it that the same schema and data can be compact in SQL Server but noticeably larger in PostgreSQL? Why do DBAs sometimes panic after migrating, when they see tables consuming 20 – 40% more disk space? And how can concepts like Column Tetris help?
If you are interested in learning how to transition your SQL Server knowledge to PostgreSQL, I highly recommend to check-out my Live Training PostgreSQL for the SQL Server Professional that I run on November 26 – 27, 2025.
The rest of this post digs into these questions, explains why PostgreSQL rows are often bigger, and shows with real examples how alignment and padding make the difference.
Row Storage in SQL Server
SQL Server stores rows inside 8 KB pages. Each row has a small header (4 bytes plus a null bitmap), followed by all fixed-length columns in the order they are defined, and then variable-length columns tracked via an offset array. Crucially, SQL Server does not enforce alignment rules for fixed-length types. That means you can place a BIT column, then a BIGINT, then another BIT, and SQL Server will pack those bytes back-to-back with no wasted space.
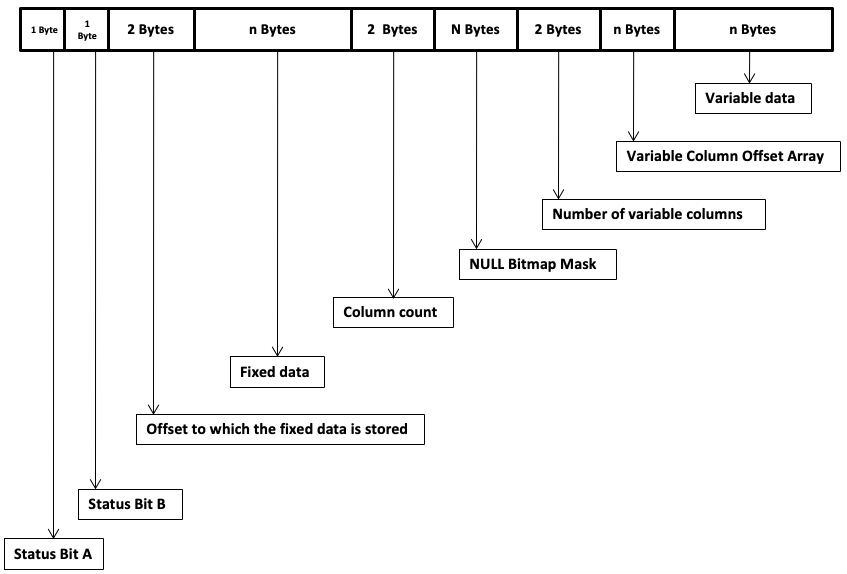
Let’s see this in action:
-- SQL Server
CREATE TABLE T_BadOrder
(
a BIT, -- 1 byte
b BIGINT, -- 8 bytes
c BIT -- 1 byte
);
INSERT INTO T_BadOrder VALUES (1, 42, 0);
-- Measure the row size: 10 bytes
SELECT DATALENGTH(a) + DATALENGTH(b) + DATALENGTH(c) AS payload_bytes
FROM T_BadOrder;
-- Inspect average physical row size: 16 bytes (4 bytes row header + 10 bytes payload + 2 bytes column count for NULL bitmap mask)
SELECT avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('T_BadOrder'), -1, NULL, 'DETAILED')
WHERE alloc_unit_type_desc = 'IN_ROW_DATA';The payload adds up to 10 bytes, plus the row header and null bitmap – in sum 16 bytes. The important point: no padding bytes are inserted between columns a and b.
Row Storage in PostgreSQL
PostgreSQL takes a stricter approach. Every row begins with a tuple header (23 bytes) containing metadata used by MVCC (transaction IDs, visibility flags, etc.), followed by an optional null bitmap, and then the column values in the order they are defined.
Unlike SQL Server, PostgreSQL enforces data type alignment:
- BOOLEAN requires 1-byte alignment
- SMALLINT requires 2-byte alignment
- INT requires 4-byte alignment
- BIGINT, double precision, and timestamp require 8-byte alignment
If a column does not naturally begin on the right boundary, PostgreSQL inserts padding bytes to move it forward. Here’s the same table in PostgreSQL:
-- PostgreSQL
CREATE TABLE t_bad
(
a boolean, -- 1 byte (+7 bytes padding)
b bigint, -- 8 bytes (requires 8-byte alignment, therefore the padding on the previous column)
c boolean -- 1 byte
);
INSERT INTO t_bad VALUES (true, 42, false);
-- Measure the actual row size: 41 bytes
SELECT pg_column_size(t) AS row_bytes
FROM t_bad t;In this case, PostgreSQL stores a in 1 byte, then inserts 7 bytes of padding so that column b can start on an 8-byte boundary. After column b, column c takes 1 byte. The total payload is already larger than in SQL Server, and this doesn’t even account for PostgreSQL’s larger row header.
If you order the column accordingly regarding their necessary padding, the storage requirements are getting smaller:
-- PostgreSQL
CREATE TABLE t_good
(
b bigint, -- 8 bytes
a boolean, -- 1 byte (no padding!)
c boolean -- 1 byte
);
INSERT INTO t_good VALUES (42, true, false);
-- Measure the actual row size: 34 bytes (7 bytes less, because no column padding was needed)
SELECT pg_column_size(t) AS row_bytes
FROM t_good t;Instead of 41 bytes, the record size is now only 34 bytes, because there was no padding necessary for column a.
Always order your columns accordingly, beginning with the largest ones – down to the smallest ones!
The Role of Variable-Length Columns
The story gets even more interesting with variable-length columns. In SQL Server, variable-length data is tracked via an offset array at the end of the row. In PostgreSQL, every variable-length value (TEXT, VARCHAR, BYTEA, NUMERIC, etc.) carries its own 4-byte varlena header. Consider the following two table definitions:
-- PostgreSQL: bad column order
CREATE TABLE bad_order
(
a boolean,
b bigint,
c int,
d timestamp,
e smallint,
f varchar(20),
g numeric(18,2)
);
-- PostgreSQL: good column order
CREATE TABLE good_order
(
b bigint,
d timestamp,
c int,
e smallint,
a boolean,
g numeric(18,2),
f varchar(20)
);
-- Insert sample data
INSERT INTO bad_order (a,b,c,d,e,f,g)
SELECT
(i % 2 = 0),
(random()*1e9)::bigint,
(random()*1e5)::int,
to_timestamp(1420070400 + (random()*1e6)::int),
(random()*32000)::int::smallint,
substr(md5(random()::text), 1, (random()*20)::int),
((random()*1e7)::bigint)::numeric / 100.0
FROM generate_series(1,1000000) i;
INSERT INTO good_order
SELECT b,d,c,e,a,g,f FROM bad_order;
-- Measure average row size
SELECT 'bad_order' AS tbl, avg(pg_column_size(t)) AS avg_row_bytes FROM bad_order t
UNION ALL
SELECT 'good_order', avg(pg_column_size(t)) FROM good_order t;In practice, the table bad_order wastes significant space (77 bytes on average) because of misalignment and poor column order. The table good_order, by contrast, keeps wide fixed-length types first and variable-length types at the end, minimizing padding (66 bytes on average).
Why PostgreSQL Rows Are Larger
Three main factors explain why PostgreSQL rows are usually larger than SQL Server rows after migration:
- Tuple header size: PostgreSQL rows carry ~23 bytes of metadata versus SQL Server’s 4-byte header.
- Alignment padding: PostgreSQL inserts padding to maintain alignment for fixed-length types. SQL Server does not.
- Variable-length overhead: Every variable-length field in PostgreSQL carries its own 4-byte header.
Playing “Column Tetris”
The good news is that PostgreSQL gives you control. Because columns are stored exactly in the order they are defined, you can save a surprising amount of space just by rearranging them. Place wide fixed-length columns first, followed by medium-sized ones, then smaller ones, and only then the variable-length columns. This is the essence of “Column Tetris”: carefully arranging your schema to minimize gaps and wasted space.
It may feel strange to spend time on column ordering – something SQL Server DBAs rarely think about – but in PostgreSQL it can directly translate into storage savings, better cache efficiency, and less I/O.
If you are interested in learning how to transition your SQL Server knowledge to PostgreSQL, I highly recommend to check-out my Live Training PostgreSQL for the SQL Server Professional that I run on November 26 – 27, 2025.
Summary
When your tables grow larger after migrating from SQL Server to PostgreSQL, it isn’t a bug or inefficiency. It’s a direct result of PostgreSQL’s design choices around row headers, alignment, and varlena storage. These choices enable powerful features like MVCC and predictable performance across architectures, but they also mean you can’t expect a one-to-one match in storage size.
The good news is that with a bit of planning – playing “Column Tetris” and choosing appropriate types – you can bring PostgreSQL’s storage footprint much closer to SQL Server’s while still benefiting from its advanced features.
Thanks for your time,
-Klaus